
The AI Performance Triangle: Why Every Company’s Results Look Different
Remember those company examples from Pilot Purgatory who all had different versions of what “success” meant?
Company A: Pass/fail accuracy (not percentages), built their own AI, “as long as it’s not completely wrong”
Company B: 95% accuracy, built their own AI, 4-minute response times
Company C: 75-80% accuracy, bought AI, high refusal rate to prevent hallucinations
All three scaled successfully. All three have happy agents. All three claim “success.”
How is that possible?
Because they’re each optimising for different things.
Where This Came From
I watched a Solution Architect explain this to a Product Manager who wanted all three: high accuracy, instant responses, and reasonable costs within pre-existing license fees.
The PM kept pushing. “Can’t we just optimise the prompts?” “What if we cache more?” “Can’t we use a faster model?”
The SA pulled up a whiteboard. Drew a triangle. Labelled the vertices: Quality, Speed, Cost.
“Pick two. Any two. But you can only pick two.”
The PM stared at it. “But the demo showed all three working together.”
“The demo showed 3 queries we selected in an environment with no load. You want to process 50,000 queries per day across multiple regions and customers with real data. Physics now apply.”
That’s when I understood why every vendor’s marketing pitch focuses on a different “success” metrics. They’re not lying. They’re measuring different optimisations.
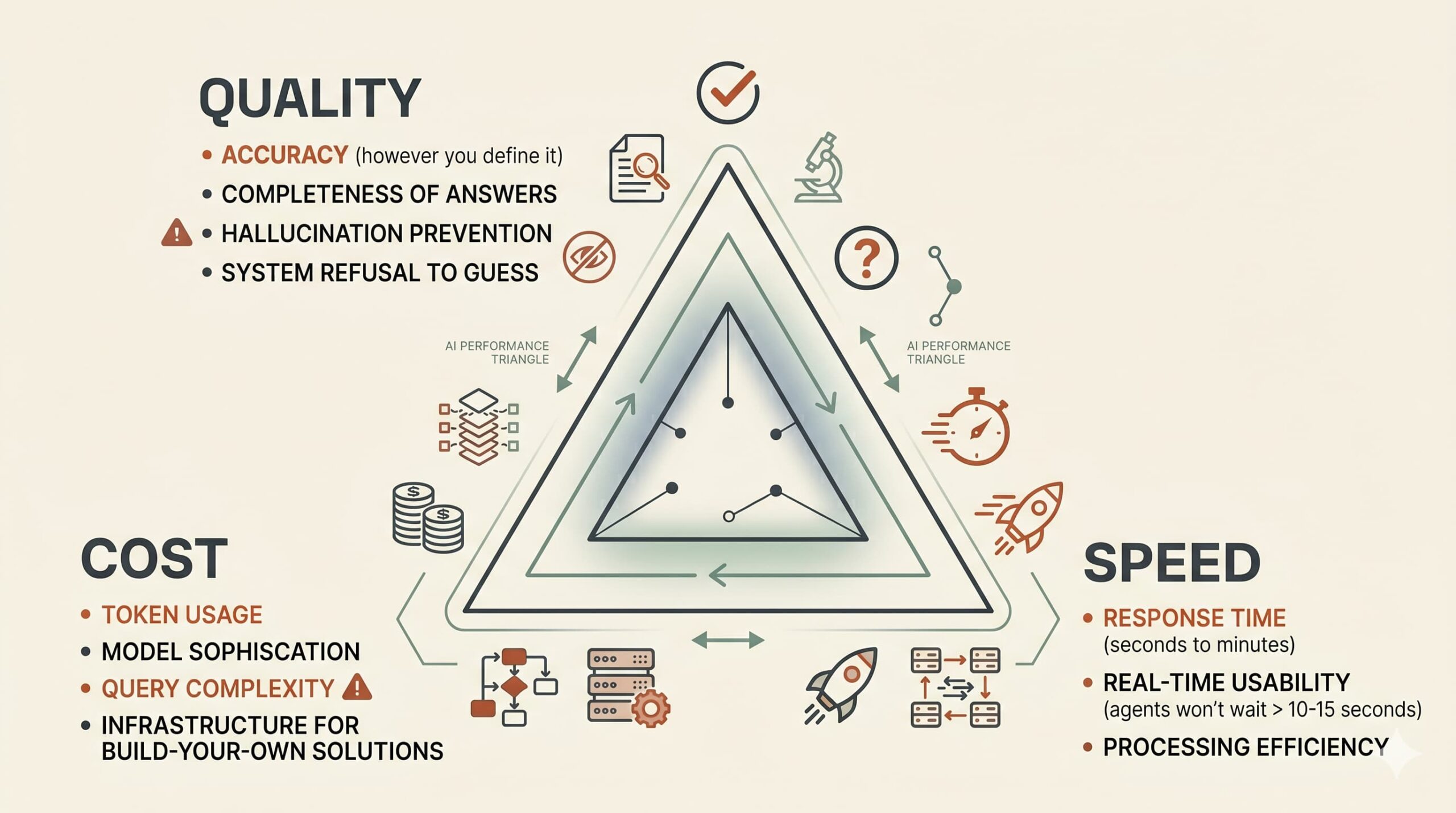
The AI Performance Triangle
Every AI system balances three factors: Quality, Speed, and Cost.
You can optimise two. The third will suffer. No exceptions.
Pick two. The third always gives way.
Click any edge of the triangle to choose your two priorities, and see what gets sacrificed in return.
The Three Vertices
QUALITY means accuracy (however you define it), completeness of answers, hallucination prevention, and how often the system refuses to guess.
High quality requires sophisticated models (expensive), thorough verification (slower), and stricter prompting (more refusals).
SPEED means response time (seconds to minutes), real-time usability (agents won’t wait beyond 10-15 seconds), and processing efficiency.
High speed requires less verification (lower accuracy), simpler processing (less complete answers), or expensive models that process faster.
COST means token usage, model sophistication, query complexity, and infrastructure for build-your-own solutions.
Low cost requires simpler models (lower accuracy), less processing (slower), or limited complexity (less complete answers).
Real Company Examples
Company A: Speed + Cost (Sacrificing Quality)
Built their own AI. High-volume, routine queries.
What we know: They use pass/fail, not percentages. “As long as it’s not completely wrong, we call it accurate. Even if it leaves information out or adds something extra, if part of the answer is correct, that’s a pass.”
What this tells us: They’re optimising for speed and cost, not precision. They built their own system (controlling infrastructure costs) and set a low bar for “accurate” (allowing fast processing).
Company B: Quality + Cost (Sacrificing Speed)
Built their own AI. Regulated industry requiring high accuracy.
What we know: 95% accuracy. Response times of 4 minutes. Built their own system to control costs.
What this tells us: They’re optimising for accuracy and cost containment. Building their own system gave them control over infrastructure spend, but achieving 95% accuracy without premium models means accepting longer processing times.
Company C: Quality + Speed (Sacrificing Cost)
Bought AI from a vendor. Complex product knowledge, need real-time assistance.
What we know: 75-80% accuracy with a “fully locked down system that refuses to answer a question to prevent hallucinating.” High refusal rate, agents sometimes get “I don’t have enough information to answer that.”
What this tells us: They’re optimising for speed (bought vendor solution for fast deployment) and quality control (preventing hallucinations matters more than answer completeness). The cost tradeoff shows up in their willingness to pay for a vendor solution and accept 15-20% refusal rates.
Why There’s No Standard Framework
Company A redefines “accurate” to make speed work. They’re measuring something fundamentally different.
Company B gets impressive accuracy but you’re not seeing the 4-minute wait times that make it possible.
Company C prevents hallucinations but you’re dealing with 20% refusal rates to achieve it.
Everyone’s showing different numbers because they’re measuring different optimisations.
That’s the gap. That’s why you can’t find a standard framework.
There isn’t one framework. There are three, depending on which constraint you’re willing to accept.
And that’s exactly why those companies got stuck in pilot purgatory, they were trying to validate against a framework that doesn’t exist, comparing their results to vendors and peers who were optimising for completely different constraints.
What This Means for Your Validation
You can’t compare Company A’s pass/fail to Company B’s 95% accuracy to Company C’s refusal rate. They’re measuring different things because they optimised for different constraints.
The problem isn’t that these numbers are wrong. The problem is treating them as comparable.
What Demos Hide
Vendor demos show all three vertices working perfectly:
- High quality (they picked the queries)
- Fast responses (demo environment, limited scale)
- Low costs (showing license fees, not operational reality)
In production, physics reasserts itself. You’ll pick two vertices. The third will suffer.
The demo isn’t lying. It’s showing what’s possible in a controlled environment. Your production environment has constraints the demo didn’t include.
The Real Pattern
Companies that scale successfully aren’t finding ways to optimise all three vertices.
They’re explicitly choosing which two matter most, accepting the constraint on the third, and stopping the comparison game with companies making different optimisation choices.
The question isn’t “how do we validate AI against a standard framework?”
The question is “which two vertices matter most to our business, and what constraint can we accept?”
You can’t have all three. Stop trying. Pick your two vertices, accept your constraint, and validate against that reality.
Want to understand how companies get stuck there and what they’re actually validating? Read “Pilot Purgatory: Why No One Knows How to Validate AI”.
Which two vertices are you optimising for? Have you made a deliberate choice, or are you still trying to get the whole cake? Reply or comment, I’d love to hear which slice you chose and why.